![アイキャッチ[Stable Diffusion]](https://vertys.net/wp-content/uploads/2023/09/catch_stable_diffusion.jpg)
存在は知っていたものの、特に興味を持たなかったのは、つい数日前までのこと。
画像生成AIというものはハイエンドなグラボを搭載したPCにしか縁のないものだと思っていたら、うちのPCでも使えることがわかったので、急に興味がわきました。
…ということで、Stable Diffusion web UIをインストールして使えるようにするまでの手順を、自分用にメモメモ。
最低限必要な環境
Windows10もしくはWindows11がある程度快適に動いていること。
グラボは、NVIDIAのGeForce系が必須(CUDAが必須?)っぽい。画像生成だけならVRAMが4GB以上。学習もさせるなら最低6GB、できれば12GB以上。
ストレージは、インストールだけなら10GB程度。でも、モデルデータがひとつ2GB程度あったり、生成した画像を保存するだけの容量も必要なので、最低100GB以上は欲しいところ。
参考までに、自分の環境を。
CPU:Intel Core i5-11400
メモリ:32GB(DDR4-3200 16GBx2)
SSD:Samsung 980Pro 500GB
HDD:WesternDigital WD40EFRX 4TB
GPU:NVIDIA GeForceGTX1050Ti 4GB
インストール&初期設定手順
初めてインストールする場合は、PythonとGitを入れてから、Stable Diffusion web UI本体をインストールします。
Pythonをインストール
今回はAUTOMATIC1111のStable Diffusion web UIを使うので、Pythonが必要です。公式推奨はPython 3.10.6ですが、3.10.10でも動きました。
Windows Installer (64-bit)をクリックしてダウンロードしましょう。32bit版では、Stable Diffusion web UIが動かないようです。
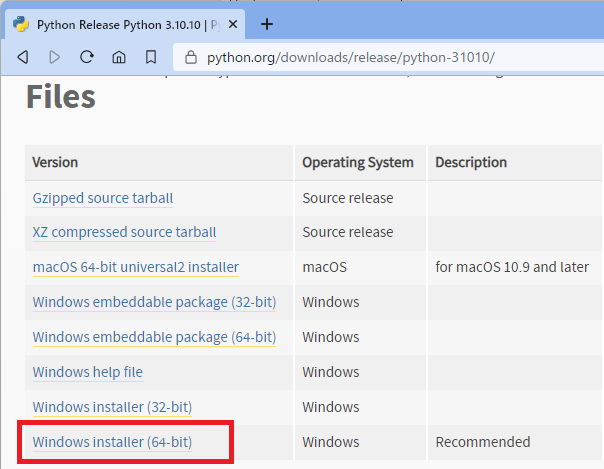
ダウンロードしたファイル「python-3.10.10-amd64.exe」を実行し、インストールします。
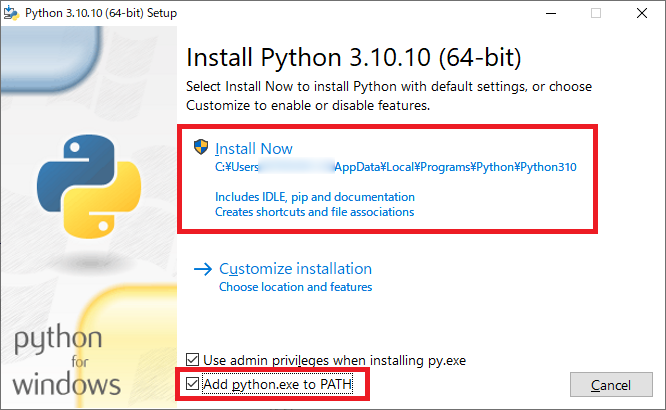
インストールの最初の画面で、下部の「Add Python 3.10 to PATH」にチェックを忘れず入れること。あとは画面の指示に従って進めていくだけ。
Gitをインストール
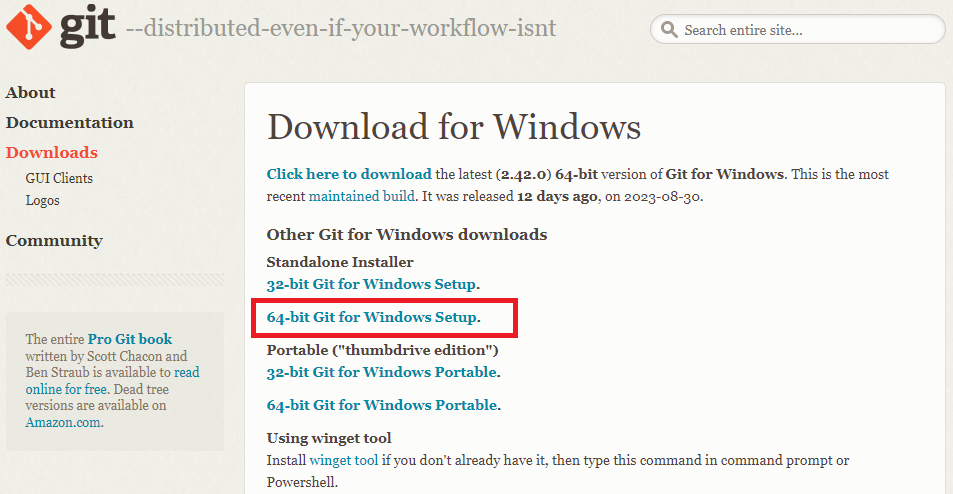
Stable Diffusion web UIをダウンロードするために、Gitをインストールします。
「Standalone Installer」の64-bit Git for Windows Setupをクリックしてダウンロード。インストールするのが嫌なら、Portable版でも大丈夫だと思いますが、未確認です。
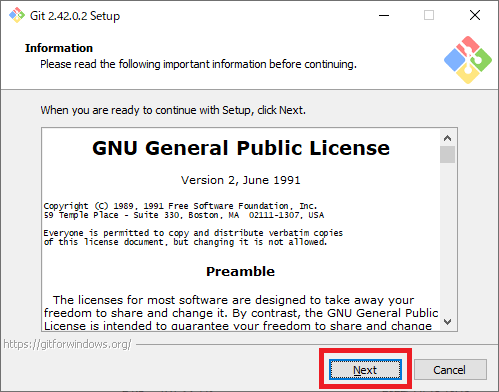
ダウンロードしたファイル「Git-2.42.0.2-64-bit.exe」を実行し、インストールします。(バージョンによって2.42.0.2の部分は可変)
インストールの画面が表示されたら、何も変更することなくひたすら「Next」をクリックしていき、最後に「Install」をクリックでOK。
Stable Diffusion web UIをダウンロード
PythonとGitのインストールが終わったら、Stable Diffusion web UIをダウンロードします。
ダウンロードした先がそのままインストール先になるので、なるべくパスが長くならないよう、ドライブの直下にフォルダを作成します。今回はDドライブの直下に「StableDiffusion」というフォルダを作成しました。
以降、「D:\StableDiffusion\」の下にStable Diffusion web UIを入れたことを前提にメモしていきます。
ターミナル(またはコマンドプロンプト、またはPowerShell)を管理者モードで起動したら、作成したフォルダへ移動します。
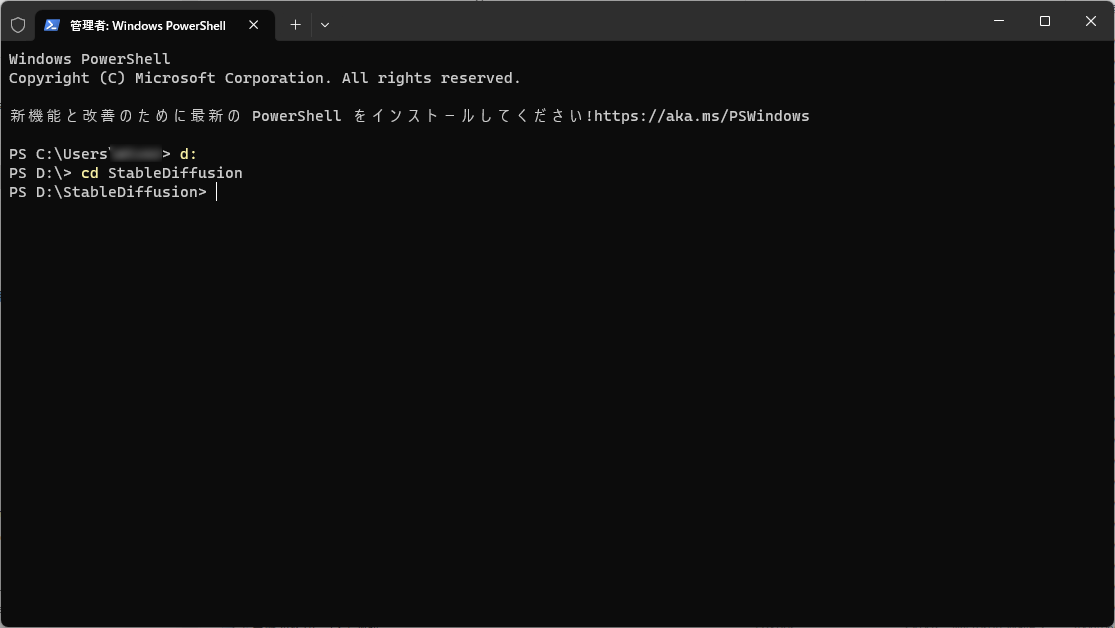
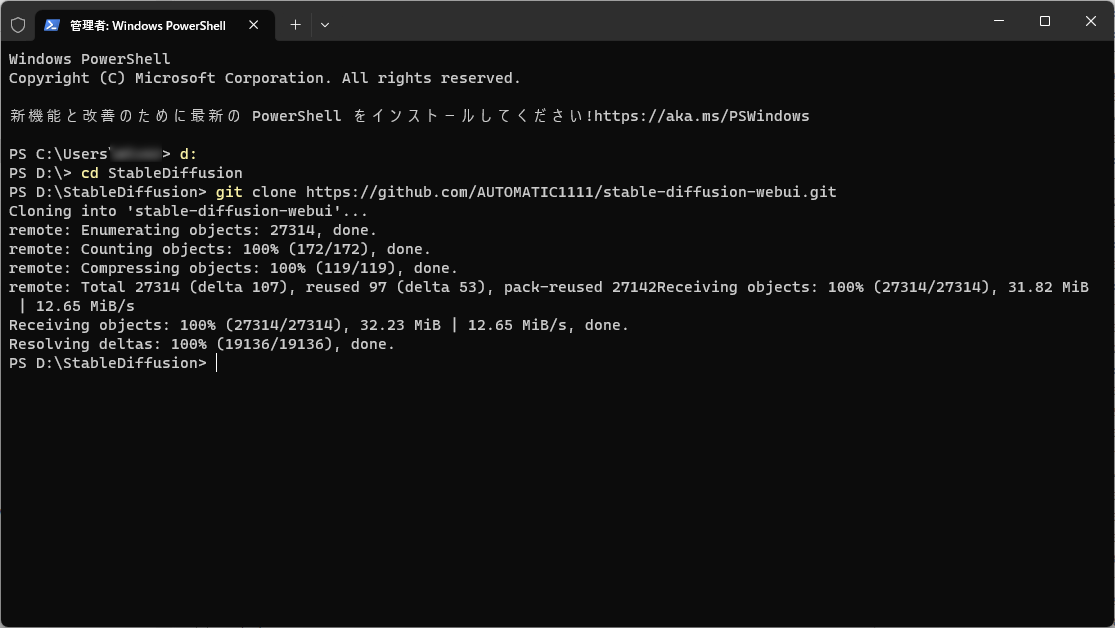
Gitコマンドでプログラム一式をダウンロードします。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitダウンロードが終わったら、ターミナルは閉じてしまってOK。
Stable Diffusion用モデルデータ準備
次に、モデルデータを用意し、以下のフォルダの中へ入れておきます。
D:\StableDiffusion\stable-diffusion-webui\models\Stable-diffusionモデルデータはSD1.x系用のもので、容量が2GB前後のものを推奨。容量が大きいモデルデータは、VRAMが足りなくなる可能性あり。
とりあえず、二次元系でおすすめとされている「Anything V5」をダウンロードして入れておきます。それ以外のモデルデータは後で。
青い「Create」ボタンの右側にあるダウンロードボタンをクリックし、「Model SafeTensor (1.99GB)」をクリックすればダウンロードされます。
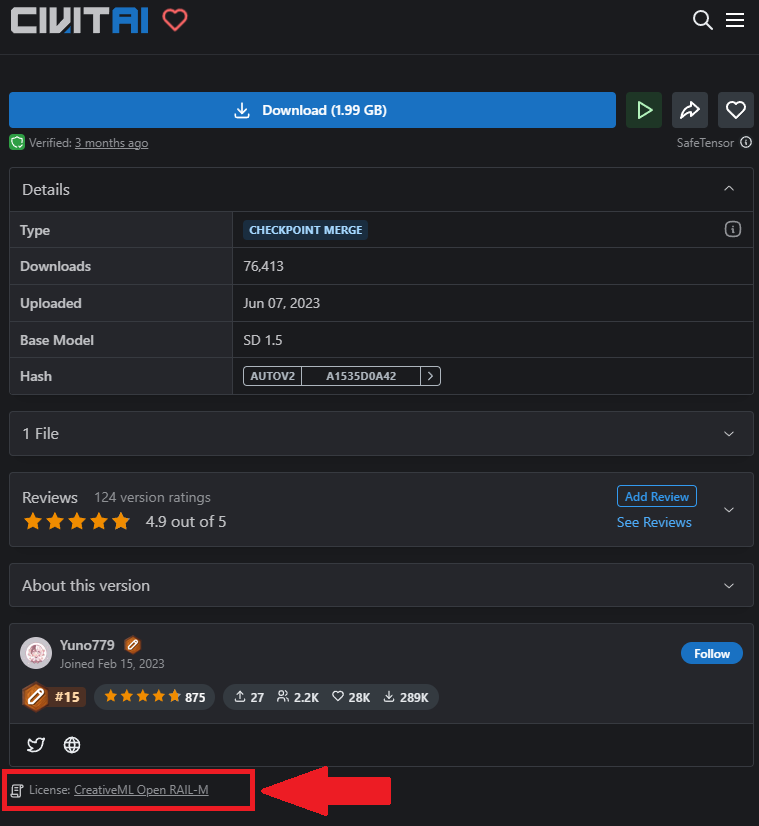
ちなみに、モデルデータにはそれぞれライセンスがあります。ライセンスが「CreativeML Open RAIL-M」となっているものは、生成した画像を使用する際にクレジット表記が不要だったり、生成した画像を販売することも許可されています。
しかし、上記Anything V5が置かれているCIVITAIというサイトでは、「CreativeML Open RAIL-M」というライセンスにさらに条件を付けることが可能になっているので、モデルデータ個別に条件をよく確認して使用した方が良さそうです。
「Anything V5」のライセンスは「CreativeML Open RAIL-M」のみの表記になっているので、クレジット表記不要、生成した画像の販売OKです。
Stable Diffusionの初期設定と初期起動
モデルデータを既定の場所にいれたら、Stable Diffusionを起動……する前に、VRAMが4GBしかない環境用に、メモリ周りの設定を行います。
D:\StableDiffusion\stable-diffusion-webui の下にある「webui-user.bat」をメモ帳などのエディタで開き、「COMMANDLINE_ARGS」にパラメータを追記します。
set COMMANDLINE_ARGS=--xformers --medvramちなみに、「--medvram」を「--lowvram」にすれば、VRAMが2GBの環境でも動かすことができるらしいのですが、2GBのGT710を積んだPC、2GBのQuadro M1000Mを積んだPCでは、エラーになってしまい起動できませんでした。
パラメータを追記して上書き保存したあと、「webui-user.bat」を実行します。
初めて起動した場合は、必要なファイル群をダウンロードしてインストールしてくれるので、終わるまで待ちましょう。インストールが終われば、ブラウザが開いてStable Diffusion web UIの画面が表示されます。
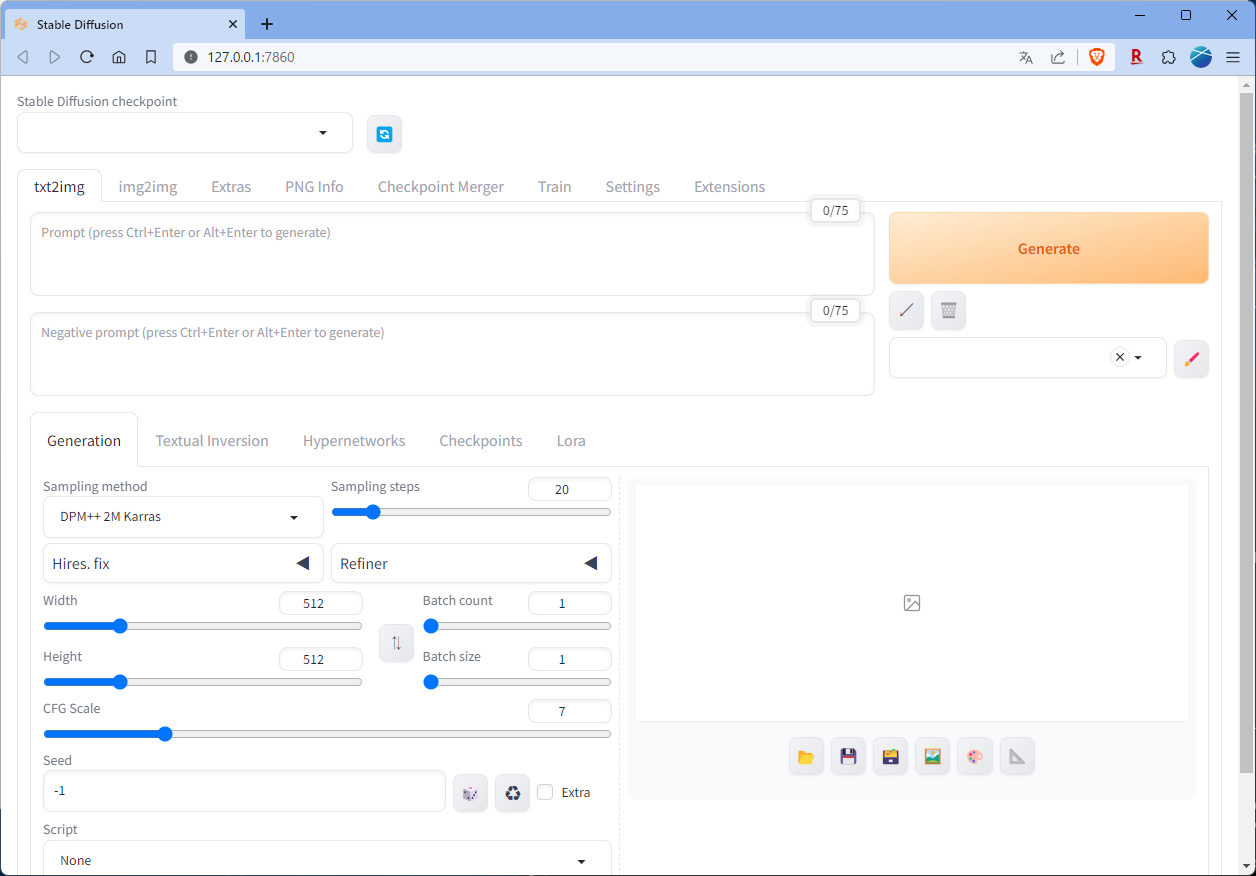
もし自動でブラウザが起動しなかった場合は、「Running on local URL: http://127.0.0.1:7860」と表示されたあと、「Ctrl]キーを押しながらURLをクリック。もしくは、自分でブラウザを起動して、URL欄に入力してもOK。
画像を生成してみる
とりあえず、正常に動くかどうかの確認ということで、何でもいいので画像を生成してみます。
左上の「Stable Diffusion checkpoint」のプルダウンから、モデルデータを指定します。今は「Anything V5」しか入れていないので、「Anything V5」を選択。
「Prompt」という入力欄に、生成したい画像のキーワードや特徴などを入力します。基本的には、カンマやスペース区切りで75個まで。右上にカウンタがついているので、それを参考に。
お試しで少女1人を生成してみます。「1girl」と入れておきます。
その下の「Negative prompt」には、生成して欲しくないキーワードや特徴などを入力します。こちらも75個まで。
健全な絵を生成してほしいので「nsfw」と入れておきます。
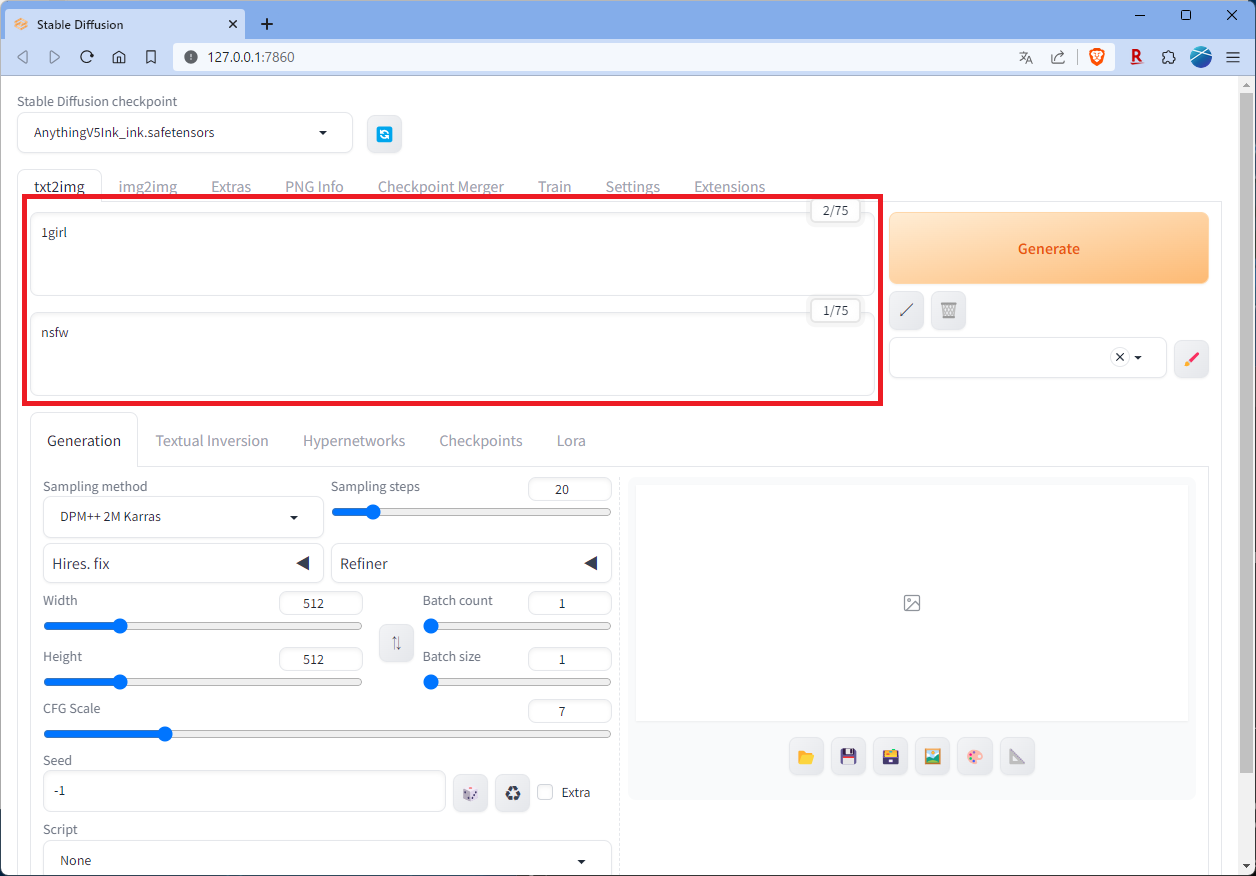
他にも細かい設定が行えますが、お試しなのでこれで生成してみます。右上のオレンジ色の大きなボタン「Generate」をクリック。
画像の生成が始まりました。
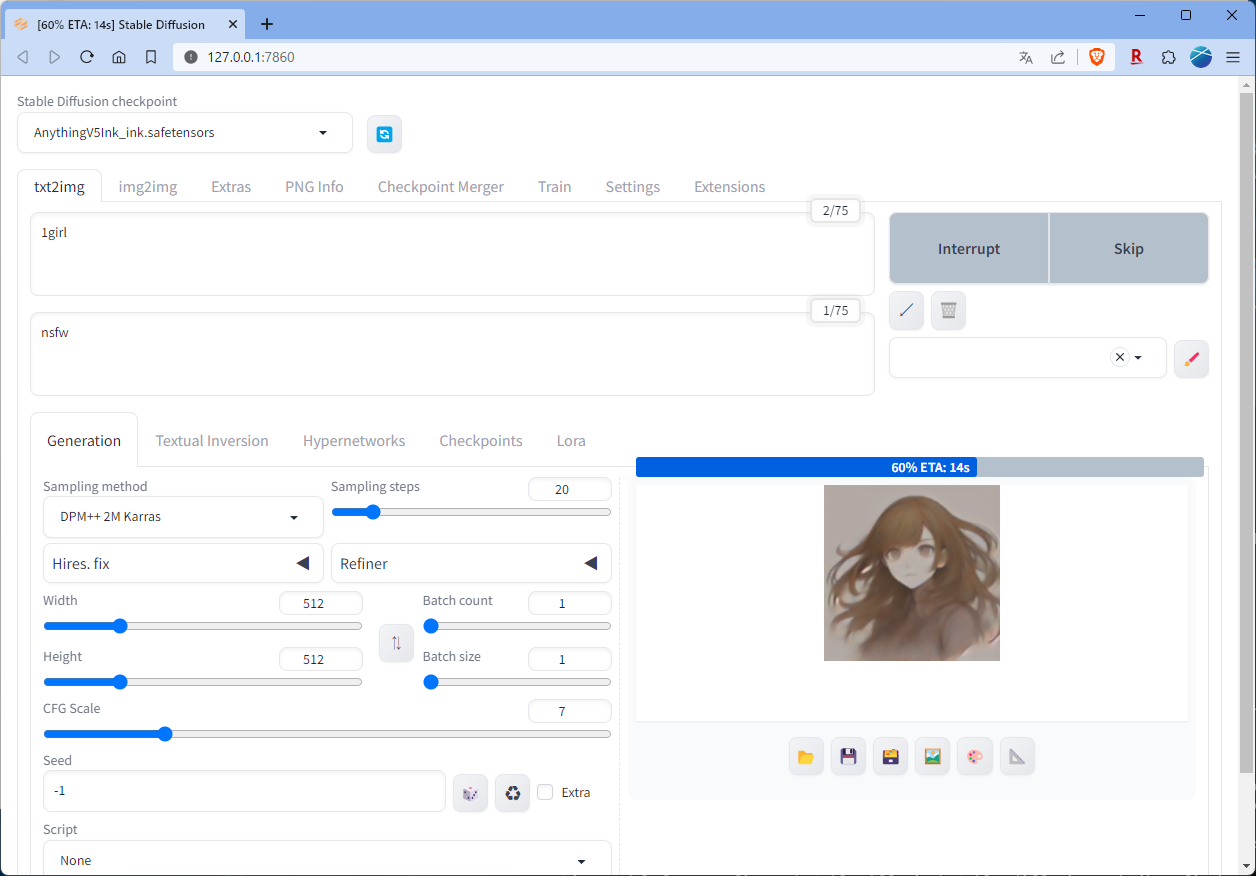
自分の環境で約30秒ほど。1枚の絵が完成しました。
生成された絵は、D:\StableDiffusion\stable-diffusion-webui\outputs\txt2img-images\yyyy-mm-dd(yyyy-mm-ddは画像を生成した年月日)の下に保存されています。
初めて生成した絵は、こんな感じ。

すごいですね。たった30秒でここまでの絵が描けるなんて。
ちなみに、「Batch count」の値を増やすと、その枚数だけ絵を生成してくれるようです。続けて2枚生成してみました。
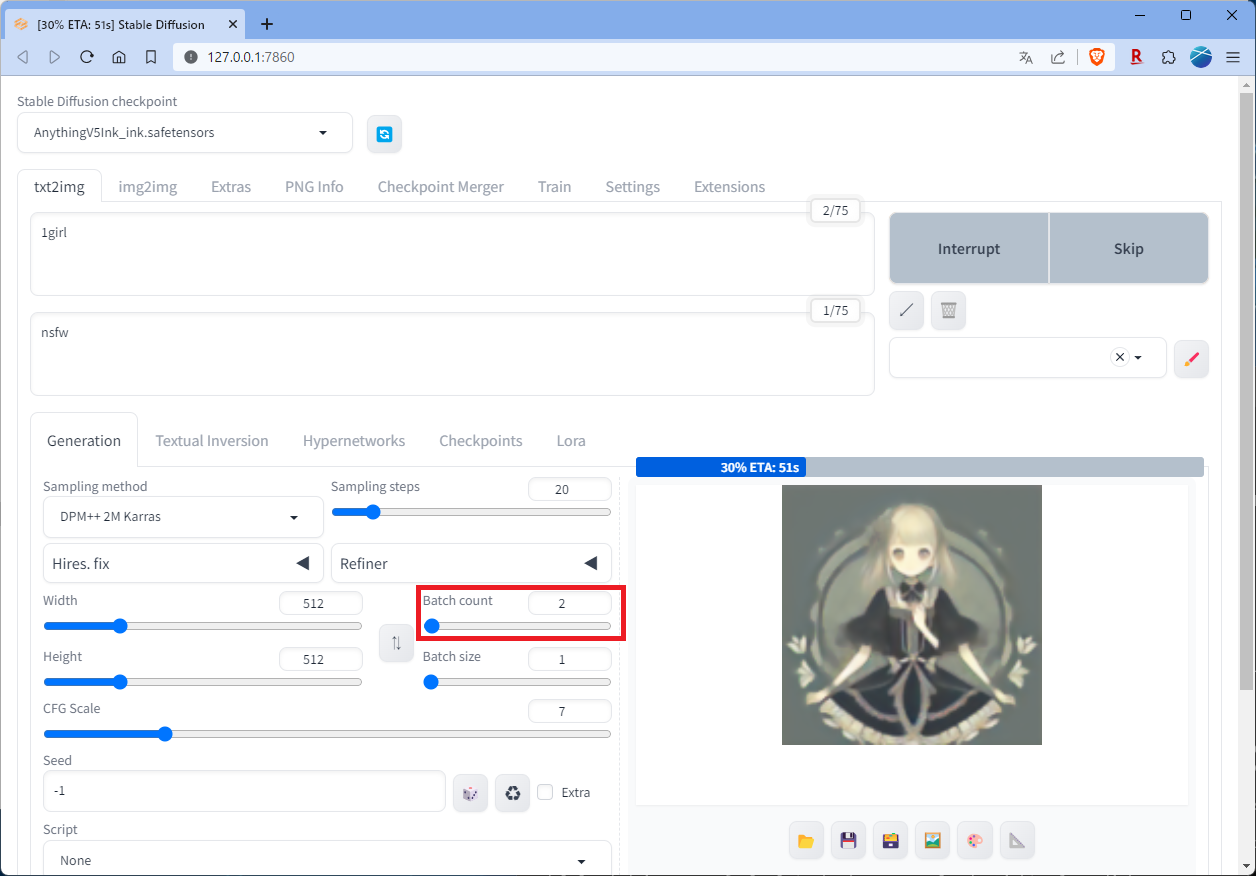
生成された2枚の絵がこちら。


あとは、プロンプトに入れるワード、ネガティブプロンプトに入れるワードを練りこんでいけば、よりハイレベルな絵が生成できる、ということですね。
また、モデルデータによって絵柄が変わったり、得意・不得意もあるようなので、その辺は少しずつ調べていこうと思います。
さいごに
ということで、世間からは出足がだいぶ遅れましたが、ようやくStable Diffusion web UIを使い始めてみました。
実際に使ってみると、プロンプトに入れるワードに悩んだり、モデルデータを探してみたりと、楽しいものですね。それなりにいいものができたら、どこかで紹介してみたいものです。
ちなみに、アップスケールする処理も追加すると、自分の環境では1枚の絵の生成に3分強かかります。夜、寝る前に仕掛けておけば、6時間睡眠として、起床するまでに約100枚ほど生成できる計算になります。
おかしな絵が生成されることもそれなりにあるので、たくさん生成しておいて良さそうな絵だけを残す、というやり方が、今のところはベストでしょうか。良さそうな絵が生成される確率を上げるためにも、ネガティブプロンプトを工夫してみることが大事ですね。
それでは、今日もお疲れ様でした!
コメント